☁️ 프론트엔드의 한계에 부딪혔을 때, AWS 친구들을 부르는 법구버전 브라우저에서 PDF 뷰어 문제가 계속 발생해서 S3 + Lambda를 활용해 PDF를 이미지로 자동 변환하는 서버사이드 솔루션으로 근본적으로 해결했고, 프론트엔드 개발자도 백엔드/인프라까지 알아야 진짜 문제 해결이 가능하다는 걸 깨달았다는 이야기2025년 8월 27일
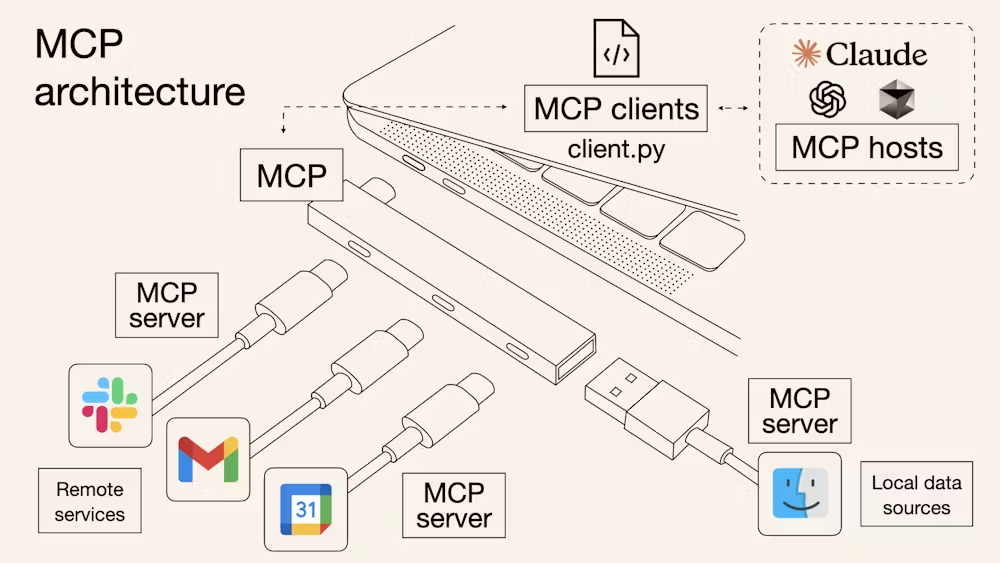
🔌 개발한 서비스에 MCP를 녹여낸다면?사내 전자동의서 에디터의 불편한 사용성 문제를 해결하기 위해 MCP(Model Context Protocol)를 도입해 Claude Desktop과 연동한 결과, 기존에 별도 UI 개발이 필요했던 목록 조회, 검색, 분석 기능들을 대화만으로 처리할 수 있게 되어 서비스 기능이 자연스럽게 확대되는 효과를 얻었지만, LLM이 의도한 방향으로 정확히 동작하게 하려면 아직 상세한 가이드가 필요한 상황이다.2025년 7월 13일
프론트엔드 구조, 나만의 레이어드 레시피 🍰기존 프로젝트의 복잡한 구조를 개선하기 위해 백엔드의 계층화 패턴을 프론트엔드에 적용했는데, 프레젠테이션, 비즈니스, 퍼시스턴스, 데이터베이스 계층으로 나누되 프론트엔드 특성에 맞게 외부 API와 Web Storage를 데이터 계층으로 대체했습니다. 실제 구현 과정에서는 초기 설계의 80%만 이행되었고, 도메인별 분리보다는 페이지 경로 기준으로 비즈니스 로직을 관리하는 방식으로 전환했으며, FSD(Feature-Sliced Design) 방식을 참고하여 각 라우트별로 컴포넌트와 훅을 묶어 관리하는 구조로 발전시켰습니다.2025년 4월 13일
React Query의 무한 스크롤무한 스크롤은 사용자가 페이지를 내릴 때마다 자동으로 데이터를 추가로 불러와 보여주는 UX 방식이다.Intersection Observer와 React Query의 useInfiniteQuery 훅을 활용하면 효율적으로 무한 스크롤을 구현할 수 있다. 핵심은 관찰 대상이 뷰포트에 들어오면 다음 페이지 데이터를 불러오고, 마지막 데이터까지 자연스럽게 이어주는 것이다.2023년 4월 17일
간단하게 사용해보는 React QueryReact에서 데이터 패칭과 상태 관리는 복잡해질 수 있는데, React Query를 사용하면 데이터 패칭, 캐싱, 동기화, 뮤테이션 등을 간편하게 처리할 수 있다. useQuery와 useMutation 훅을 활용하면 로딩, 에러, 최신 데이터 반영 등 다양한 요구사항을 쉽게 구현할 수 있으며, invalidateQueries, Optimistic Updates 등 고급 기능도 지원한다. 적절한 옵션 설정과 쿼리 키 관리로 효율적인 데이터 최신화와 캐싱이 가능해진다.2023년 2월 20일
(AWS)VPC, EC2, ALBAWS에서 EC2 인스턴스를 사용하려면 VPC, 서브넷, 라우팅 테이블, 인터넷 게이트웨이 등 네트워크 환경을 먼저 구성해야 한다.EFS는 여러 인스턴스에서 공유 가능한 네트워크 파일 스토리지이며, Application Load Balancer는 트래픽을 여러 대상에 분산시켜 안정적인 서비스를 제공한다. 각 리소스의 보안 그룹, IP, 연결 설정 등 기본 개념과 실습 과정을 따라가면 AWS 인프라를 효과적으로 구축할 수 있다.2022년 6월 24일
(AWS)S3, CloudFront 간단한 사용기AWS S3는 대용량 데이터를 저장하는 객체 스토리지 서비스로, 버킷을 생성해 정적 웹사이트를 호스팅할 수 있다.CloudFront는 전 세계에 분산된 CDN 서비스로, S3와 연동해 정적 웹사이트의 콘텐츠를 빠르고 효율적으로 전달한다.S3 버킷 정책과 퍼블릭 엑세스 설정, CloudFront 배포 설정을 통해 웹사이트 성능과 접근성을 높일 수 있다.2022년 6월 17일